-
Each time I hear about 8bit images and 6-7 stops I just can't bear it...
Just to make it into extreme to show stupidity.
Let's make it 1bit.
- 0 - will be defined as "low building".
- 1 - will mean "high building".
Dynamic range will be ratio between low and high buildings heights.
One stop just means that this ratio is equal to 2, two stops that it is 4, etc
Did you noticed that we never referenced specific heights numbers here?
In reality we can define "low building" as 1 meter and "high building" as 8000 meters (we are free to do it, can also use other definition).
Hence we have 13 stops, using 1 bit.
Well, you can say, but we are losing all buildings in between. After encoding they will become either "high" or "low".
May be this is where the limit is? Well, no not here.
For 8bit we have 256 separate values now. We can make out definition as
- 0 - lowest building
- 1 - one that is 2 times higher
- 10 - one that is 4 times higher
- 11 - one that is 8 times higher
- etc
So it'll be total 256 stops. :-)
We'll talk where the limit lies soon..
-
A calibrated studio SDR monitor will emit a maximum of 100 nits. Where a normal SDR studio monitor may reproduce black between 1 and 2 nits, the Canon DP-V2410 HDR monitor is capable of reproducing black at 0.025 nits.
From canon sponsored HDR diatribe
This is pure lie, here is not too good on camera IPS (VA is much better)
- White field - 122 cd/m2
- Dark field - 0,183 cd/m2
Lie is around 10x times, even for IPS. Desktop IPS monitors are better. And VA are much better.
Samsung typical TV (VA panel)
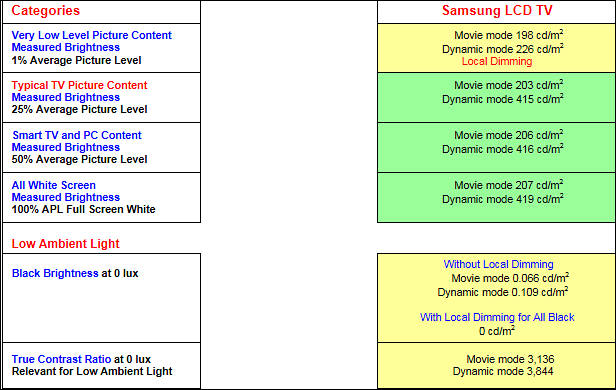
Most important for HDR (especially LCD based) lie is to avoid human vision science and especially how adaptation works.
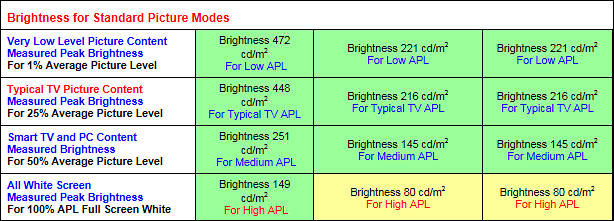
OLED measurements (standard 2016 LG TV)
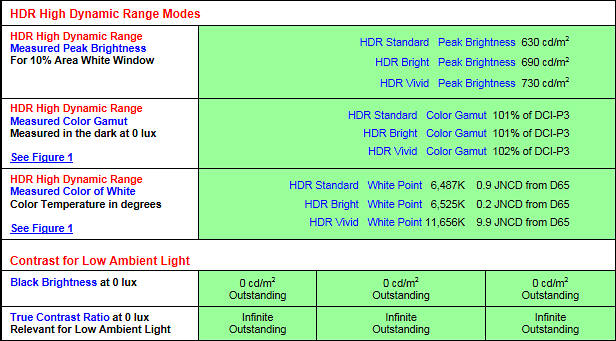
Yet plasma like behavior
 sample849.jpg616 x 341 - 76K
sample849.jpg616 x 341 - 76K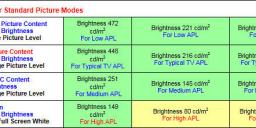 sample850.jpg614 x 221 - 63K
sample850.jpg614 x 221 - 63K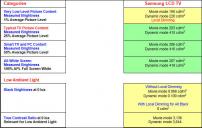 sample851.jpg616 x 390 - 67K
sample851.jpg616 x 390 - 67K -
@caveport i think this thread should be brought back to @Vitaliy_kiselevs topic.
Which personally I think is quite interesting. All computer storage systems have bit depth. Even UTF-8. So this discussion is intrinsic of all computer storage systems, which digital video is just one of.
-
@ alcomposer "Can we please not get personal?" and "Gosh I didn't know you always do compositing on EVERY multicam shoot you do!"
I would really like to see any system that can composite 100 streams of 4k in real time! Current editing systems are struggling with 3+ layers in real time.
I made no mention of multicam or Fusion. I think this is the end of a non-productive discussion. The difference in our knowledge of the underlying technology is making effective communication impossible.
Also "Because the audio recording will sound much more real than the video recording." I laughed so hard! What a fabulous dry-humour joke! I love it!
-
So when I do a compositing job with over 50 layers, are you suggesting that I really can't see all my layers and I'm only imagining them? Your knowledge of video systems needs a little refresh!
Gosh I didn't know you always do compositing on EVERY multicam shoot you do! Unlike audio which is ALWAYS composited together when using multiple microphones.
Normally I only open up Fusion for VFX work. I didn't think that was the discussion.
Also, normally I don't ALWAYS use video in compositing, sometimes mattes, or deep pixel layers. So no, all those channels are not always going to be seperate video media assets, as they are in audio land.
Also currently most compositors are not optimised for GPU acceleration (CUDA can also be slow here as well, simply using GLSL could solve speed issues). Which is a huge problem. Even simple blend operations are still carried out on the CPU, something that a shader could easily achieve, at 32bit precision, in a fraction of the time.
Even decoding of video could be shifted from CPU to GPU, something that needs to happen asap. There are a few accelerated codecs (such as HAP) however they are not lossless enough for production work, only realtime work. (Look into Touch Designer, Vuo for realtime video mixing / effects processing).
Can we please not get personal? I would love to have a great discussion about this without being questioned, I have never questioned your knowledge. I'm sure we are all professionals here, with great bodies of work. It's not helpful having a discussion in which we just throw random: "your knowledge needs a refresh" comments.
This whole discussion has got out of hand. I've greenscreened 360 VR content with up to 100 layers 4k, and was able to playback in realtime... so no need for a refresh.
I don't understand the strawmanning, considering my last comment on this super offtopic debate:
Actually, I have realised though this discussion that there is a huge problem with my logic: We need a way to quantify the quality of both audio and video capture systems. If audio is "much simpler" then we have to quantify at what "quality" is it simpler. Lets say we capture an SD video image of an orchestra, and a super high audio recording: are they both similar? No. Why? Because the audio recording will sound much more real than the video recording. I would suggest that 4k 60p is the equivalent of a good audio recording in making the viewer feel like they were there "in the room". So with that logic, and definition of similar quality then yep, video wins the complexity race.
All because I would like to use video like audio, I didn't think this was a debatable topic. Video is getting easier to work with, try to do 100 4k layers realtime on a 10 year old PC.
As was mentioned before: video is transitioning into a more robust format similar to the evolution of audio did, (16 bit -> 24 bit).
Also remember 32 bit audio is just around the corner, with AD systems that employ the use of multiple AD stages to make distortion and peeking a thing of the past. Maybe audio is the medium that is playing catch up! ;-)
-
It all went.... well... far.
-
@alcomposer "But 32 video channels currently can only be edited together, and viewed one at a time, unlike audio."
So when I do a compositing job with over 50 layers, are you suggesting that I really can't see all my layers and I'm only imagining them? Your knowledge of video systems needs a little refresh!
-
In digitization of both audio and video, the two main quality issues are aliasing and quantization. With audio, steep high-cut filters allow alias-free sample rates as low as 44Khz, and 24-bit ADC's have imperceptible quantization noise. Video digitization is nowhere near as clean. You can readily spot aliasing patterns in shots of standard resolution charts, and banding of smooth gradients is a frequent pitfall.
-
Actually, I have realised though this discussion that there is a huge problem with my logic:
We need a way to quantify the quality of both audio and video capture systems.
If audio is "much simpler" then we have to quantify at what "quality" is it simpler.
Lets say we capture an SD video image of an orchestra, and a super high audio recording: are they both similar? No. Why? Because the audio recording will sound much more real than the video recording.
I would suggest that 4k 60p is the equivalent of a good audio recording in making the viewer feel like they were there "in the room".
So with that logic, and definition of similar quality then yep, video wins the complexity race.
-
The thing is, 32 tracks of audio are not "experienced" at different times. If you are suggesting that 32 audio tracks are the same as 32 video tracks, that's not 100% correct either. Why? Because no-one watches 32 video angles at the same time. However the 32 audio channels are mixed together into one sound experience "at the same time".
So, obviously, if we were talking about computational video systems such as light field capture- sure-32 video angles could be merged into one super amazing video file. But 32 video channels currently can only be edited together, and viewed one at a time, unlike audio.
Lets put it this way, you can use an iPhone to film and audio record an orchestra... Or a multichannel audio desk with a RED camera. Both are capturing in the same temporal space, at the best quality in 2017. Once another camera is added you need to edit between cameras, thus we are not watching both cameras at once. One could use a split screen technique, but not for 32 HD channels.
I think I was a bit quick however in saying before that both audio and video were same complexity, rather that at the end of the day they are both utilising similar AD systems. Obviously video has much much much much more data to process.
-
@alcomposer Video digitising is way more complicated because it has spatial information which audio does not have. It is also comprised of multiple channels, each of which can be different information i.e. RGB, YUV etc. which is also very different from audio. Also the different channels can be different sample rates depending upon codec choices such as 4:2:2, 4:2:0 etc.
Quote:
"Fortunately for video, a computer can always drop a frame during playback if it gets over-worked, (miss-matched frame rates- or high complexity) in playback. Audio can not do that- as one would hear a horrid crackling sound.
So in that regard it is not simpler at all. Look into software synth design, and computer audio buffers, it is quite complex.
Also remember that high quality audio interfaces can be as expensive as a RED or Blackmagic URSA camera. With very complex designs, including word clocks, low jitter PLL etc..."
These comments don't really have anything to do with digitising complexity.
I'm also surprised you are comparing 32 tracks of audio to the RGB/YUV 3 channel encoding for video. A more accurate comparison would be 32 layers of video in a timeline, i.e. 32 similar streams processed simultaneously. I have had this kind of argument with audio engineers for many years & none of them ever been able to deliver a LOGICAL argument for why they think video digitising is as easy as audio.
I don't mean to be argumentative but I think there are gaps in your knowledge of video systems engineering and technicalities. The first post here pretty much enlightens me to the general level of understanding, even from people who claim to be knowledgable!
-
Ok a 'bit' (e.g. a 1/0 binary digital element) has whatever meaning you want to interpret it as, but when they are used in base-2 mathematics which I assume since you are discussing the concept of single-bit (as compared to multi-bit) word values, this is what I am speaking of - but at this point you can omit bits and just deal with numbers themselves and the number of divisions / distinctions between the upper and lower bound they provide.
Did not understand fully this part.
Thing that I did is just making definitions. At the stage I am talking here I am free to do such definitions.
-
Thanks for good post, but I have strong suggestion to move it to separate topic. May be leave directly related part.
You see, bits are always powers of two (e.g. 1 bit = 6 dB in these cases).
This is wrong, for example.
Ok a 'bit' (e.g. a 1/0 binary digital element) has whatever meaning you want to interpret it as, but when they are used in base-2 mathematics which I assume since you are discussing the concept of single-bit (as compared to multi-bit) word values, this is what I am speaking of - but at this point you can omit bits and just deal with numbers themselves and the number of divisions / distinctions between the upper and lower bound they provide.
However, speaking of single-bit word values, I'm curious as to what your core argument is. It reminds me "a bit" (pun intended) of the whole 1-bit DSD encoding method right now, where the bitstream is the important part and the single bit less so, but I don't think that's where you're going with it.
I'll get to whole picture step by step.
Looking forward to it!
-
@caveport the concept is not that they are the same process- or that they are comparable. The idea is that both Audio and Video are digitized in a similar way, (sampling analog values using 1:0).
Audio digitising is way simpler than video
I disagree with this statement. They are very similar. Both video and audio use AD-DA chips, video simply has greater data for a single channel. Mind you, to record an orchestra- or a large band, one can easily use 32 channels, each of which using 96-192khz sampling rates at 24 bit depth.
Fortunately for video, a computer can always drop a frame during playback if it gets over-worked, (miss-matched frame rates- or high complexity) in playback. Audio can not do that- as one would hear a horrid crackling sound.
So in that regard it is not simpler at all. Look into software synth design, and computer audio buffers, it is quite complex.
Also remember that high quality audio interfaces can be as expensive as a RED or Blackmagic URSA camera. With very complex designs, including word clocks, low jitter PLL etc...
Check out these mastering grade AD-DA interfaces: http://en.antelopeaudio.com/pro-audio-devices/
-
@alcomposer Audio digitising is way simpler than video. The processes are not comparable at all, really.
-
Digitization of light intensity is slowly working its way through similar issues as digital audio technology did decades ago. The 8-bit SoundBlaster standard ruled PC audio for years, much as 8-bit H.264 video does now. Audio digitization was eventually perfected with 24-bit capture and 16-bit playback, but 24-bit recording would require excessive storage sizes for video.
Yes! Totally agree. This has been my thoughts for a long time. Coming from audio land, video seems very much like a huge step back.
-
Digitization of light intensity is slowly working its way through similar issues as digital audio technology did decades ago. The 8-bit SoundBlaster standard ruled PC audio for years, much as 8-bit H.264 video does now. Audio digitization was eventually perfected with 24-bit capture and 16-bit playback, but 24-bit recording would require excessive storage sizes for video. The fundamental problem is that both audio and video work on logarithmic (db) rather than linear scales, and are most efficiently encoded in floating point rather than fixed-point formats. Camera sensors are digitally-sampled analog devices that currently produce 12 or 14-bit linear output, but this RAW RGB data is sensor-specific and unsuitable for direct viewing. Ideally, it should be gamma-corrected into an industry-standard flat log scale, with each color channel encoded in a 16-bit floating point format, with a 4-bit exponent and 12-bit mantissa. That would provide a 96db dynamic range with a consistent 12-bit color resolution at all levels of light intensity, from shadows to highlights.
For practical purposes, color resolution could be truncated down to 8-bits, with the 4-bit DR data packed into a separate 8-bit stream. Since DR varies at a far slower rate than color variations, simple delta-compression would reduce the DR stream to a small fraction of the size of the 8-bit color data, which could be compressed losslessly by about 50%. So it would require about 7-bits per native R, G or B sensor pixel to encode the entire sensor output with 96db DR and 8-bit color resolution.
-
This not bad humor topic :-)
-
DR. Dynamic range PHD in geriatric sensors with speciality in low gain at elder age sensors with low Dynamic range specially with CCD and early CMOS tech.
(No staked sensors and later CMOS tech)
DR. Dynamic range. Atention all mondays from 10am to 4pm.
Call secretary asistant miss vitally to make your chek in.
we dont accept HDR sensors. 10 bit or higher with latest h265 wont be atended. (Only h264 8bit prossesing)
1800-drdynamic.
-
I think you mean steps not stops.
LOL
-
Ah, ok. This will be fun then!
Looks like it will not only be maths, but also computer science a bit. :-)
-
So all discussions regarding video encoding has to be based on human perception.
No.
Again, it is isolated math only topic for now.
I SPECIFICALLY removed everything else. And will add part by part.
-
@Vitaliy_kiselev problem is all perception of images is "human perception". In nature there are extended ranges of colour such as IR range (birds etc) which do not exist in video range. Video colour range is specifically designed for human image perception system only.
Same issue is with sound, human hearing is only capable of 20khz (most only hear 16 if lucky, and young), however ultra sound exists in nature.
So all discussions regarding video encoding has to be based on human perception. This is actually how MP3 was developed, looking at human hearing system.
Even our scientific capture systems have to translate different ranges to visable human range. (Such as IR camera)
-
In your example @vitaliy_kiselev we could have 1 bit file of 100 stops of dynamic range. This would cause extreme banding. More bits less banding. (In today's tech bits should be limited to sensor native noise level, as above that we are just sampling noise better)
Please carefully read that I wrote. Do not attach here monitor or anything.
Then again, one only has to look at all the issues with 8bit distributed video on YouTube etc, (Banding) to get an idea why a 10bit display and 10bit file could help here.
Youtube use very high comporession done using cheapest algorithms on GPUs.
Noise dithering can also be used to fix such banding issues, (which can be extreme not only in skies but also others scenes). However video land doesn't like the idea of "adding" noise to images.
No one actually care that they like (actually they very much like to add "proper" film grain). It is just simple math.
Obviously this discussion is only talking about final image- not capture or sensor. So good idea to use CGI as example, or even motion graphics. If I were to generate a lovely gradient of black to white, we would need at least 8 bit image to have decent non-obvious banding.
This exact discussion is about digital images only. And do not add here perception things for now.
I talked only about DR using strict definitions.
There also must be prior research into human perception of banding and light intensity. A level at which changes of intensity disappear to the human vision system.
Humans use big brain part to "process" images. And it is very complex system with feedback loops, system dealing only with tiny bit of source information.







Howdy, Stranger!
It looks like you're new here. If you want to get involved, click one of these buttons!
Categories
- Topics List23,990
- Blog5,725
- General and News1,353
- Hacks and Patches1,153
- ↳ Top Settings33
- ↳ Beginners256
- ↳ Archives402
- ↳ Hacks News and Development56
- Cameras2,366
- ↳ Panasonic995
- ↳ Canon118
- ↳ Sony156
- ↳ Nikon96
- ↳ Pentax and Samsung70
- ↳ Olympus and Fujifilm100
- ↳ Compacts and Camcorders300
- ↳ Smartphones for video97
- ↳ Pro Video Cameras191
- ↳ BlackMagic and other raw cameras116
- Skill1,960
- ↳ Business and distribution66
- ↳ Preparation, scripts and legal38
- ↳ Art149
- ↳ Import, Convert, Exporting291
- ↳ Editors191
- ↳ Effects and stunts115
- ↳ Color grading197
- ↳ Sound and Music280
- ↳ Lighting96
- ↳ Software and storage tips266
- Gear5,420
- ↳ Filters, Adapters, Matte boxes344
- ↳ Lenses1,582
- ↳ Follow focus and gears93
- ↳ Sound499
- ↳ Lighting gear314
- ↳ Camera movement230
- ↳ Gimbals and copters302
- ↳ Rigs and related stuff273
- ↳ Power solutions83
- ↳ Monitors and viewfinders340
- ↳ Tripods and fluid heads139
- ↳ Storage286
- ↳ Computers and studio gear560
- ↳ VR and 3D248
- Showcase1,859
- Marketplace2,834
- Offtopic1,320


